Sujets et articles
Entre 2004 et 2006, des enregistrements audio ont été collectés auprès de quatre espèces de primates non humains (quatre orangs-outans, deux gorilles, trois bonobos et quatre chimpanzés) dans sept instituts différents. La relative rareté des grands singes non humains dans les populations captives limite la taille de l’échantillon pour cette classe d’âge. De plus, nous avons collecté des vidéos de quatre enfants riant dans leurs maisons privées. Les détails de la pièce d’identité, du sexe, de l’âge et du lieu d’enregistrement peuvent être trouvés dans le tableau supplémentaire. 5. Tous les sujets ont été enregistrés acoustiquement dans leur environnement domestique lors d’interactions contrôlées et ludiques avec des individus familiers, produisant des vocalisations provoquées par le jeu et les chatouilles. Dávila-Ross et ses collègues ont déjà crédité la plupart des enregistrements de chatouilles de primates non humains.4et nous avons réanalysé ces points de données originaux pour la présente étude. Cette méthode a été utilisée de manière fiable pour étudier le comportement vocal spontané chez de nombreuses espèces23. Les enregistrements ont été réalisés à l’aide d’un Sony WM-D6C avec un microphone Sennheiser ME 60 et d’un Nagra IV-SJ avec un microphone Sennheiser MKH 816. Dans toutes les installations zoologiques où des enregistrements ont été collectés, nous avons suivi toutes les directives éthiques concernant l’utilisation des animaux. Aucune approbation éthique formelle n’était requise pour les études observationnelles non invasives conformément aux directives de l’Université vétérinaire de Hanovre, affiliée au MDR au moment de l’enregistrement. Les participants étaient des nourrissons enregistrés à la maison lors d’interactions de jeu naturelles avec leur mère. Le consentement verbal a été obtenu des mères au moment de la collecte des données (il y a plus de 20 ans). Toutes les directives éthiques applicables aux participants à la recherche humaine ont été suivies.
Analyse statistique
Les fichiers audio au format WAV ont été convertis en ESPS et rééchantillonnés à 22 050 Hz. Un filtre passe-haut de 60 Hz a été utilisé pour minimiser les interférences de bruit électrique. Les enregistrements présentant une différence signal/bruit inférieure à 2 dB ont été supprimés pour augmenter la qualité des enregistrements. Si les enregistrements masqués par le bruit avec des fluctuations aléatoires ou le début/compensation de l’appel n’étaient pas clairs, ces enregistrements étaient exclus de l’étude. Il convient de noter que les enregistrements n’étaient pas totalement exempts de bruit, ce qui est normal dans la plupart des études acoustiques, mais si l’accent est mis sur les modèles temporels comme dans cette étude, l’influence de ces facteurs sera faible. Le temps de début a été fixé à 0,0 s et le décalage du courant continu introduit par l’enregistrement sur bande a été corrigé pour centrer la forme d’onde sur l’axe de tension nulle et éliminer les artefacts d’enregistrement basse fréquence. L’amplitude est entièrement normalisée. Tous les traitements ont été effectués à l’aide de X-Waves 5.3 (Entropic Research Lab, Washington, DC). Nous avons commenté le point de départ de chaque appel, sa durée et s’il était lié à la même période qu’un appel précédent. Un cri est défini comme un élément vocal continu sans coupure vocale. Suivant4les appels consécutifs appartiennent à la même correspondance si la durée de l’intervalle est inférieure à 8 millisecondes ou a le même mode. Si deux combats sont espacés de moins d’1 seconde, ils appartiennent à la même série. Nous nous sommes concentrés sur les combats comportant au moins trois cris et avons sélectionné un total de 140 combats, dont 42 bonobos, 35 chimpanzés, 34 gorilles, 13 humains et 16 orangs-outans. Nous avons utilisé le logiciel R24 calculer la durée de l’intervalle entre le début et la période suivante de l’appel à l’intérieur du combat appartenant au même combat (ci-après tkce qui suit11), pour obtenir 458 tk valeurs (bonobos 112, chimpanzés 116, gorilles 112, humains 56, orangs-outans 62).
Nous avons effectué toutes les analyses statistiques à l’aide du logiciel R24. Avant d’ajuster le modèle, nous avons créé une nouvelle variable qui code la distance phylogénétique de chaque espèce par rapport aux humains. 25. Pour tester la validité de l’approche modèle, nous avons comparé nos modèles complets avec leurs modèles nuls respectifs (contenant uniquement le facteur aléatoire) et poursuivi les tests post hoc lorsque les modèles complet et nul étaient significativement différents (Anova, avec argument chi carré).26).
Rythme de comédie
Nous avons ajusté un premier modèle linéaire à effets mixtes (Lme427; LMM1) pour examiner comment la rythmicité varie (transformée en log) en fonction de la distance phylogénétique, en utilisant l’âge en mois comme facteur de contrôle et en utilisant la troncature aléatoire des fichiers pour tenir compte de la variation entre les enregistrements. Le deuxième modèle (LMM2) incluait une interaction entre la distance phylogénétique et le contexte comportemental dans lequel le rire (jeu/chatouillement) se produisait. Nous avons calculé des pentes pour chaque niveau du facteur « contextuel » tendances fonction (emmen emballer28). Le troisième modèle (LMM3) a été ajusté pour examiner comment le taux de rire (transformé en log) variait selon les contextes de genre avec la variable de réponse, l’interaction entre la spécificité du genre et le contexte (jeu/chatouillement), l’âge individuel comme facteur de contrôle et l’identité du fichier comme interception aléatoire. Nous avons ensuite comparé les contextes x par paire pour chaque niveau emmen emballer28.
Variation de tempo
Nous avons ensuite calculé le coefficient de variation (CV) du taux de rire pour chaque enregistrement.N = 32) et cette valeur a été utilisée comme variable de réponse. Nous utilisons le quatrième modèle (LMM4) avec la distance phylogénétique et l’âge comme facteurs fixes, les traits individuels interceptés au hasard et les mesures répétées prises en compte. Nous avons utilisé R pour dériver des valeurs p pour chaque prédicteur résumé fonction. La taille limitée de l’échantillon nous a empêché d’examiner les différences potentielles entre les deux contextes.
Vérifier l’isochrone dans le rire
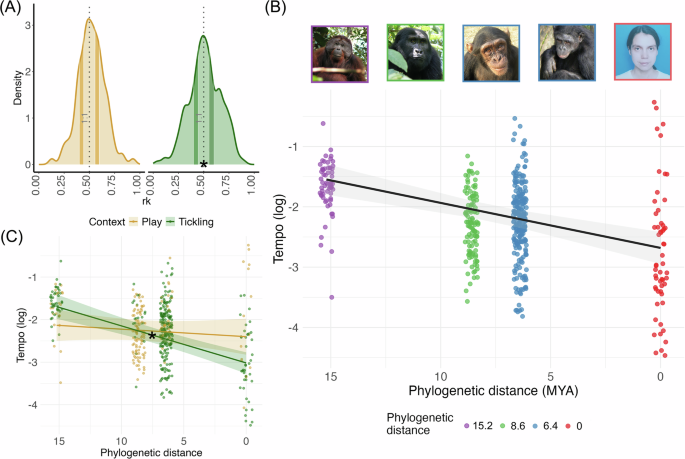
Enfin, pour évaluer la structure rythmique du rire, nous avons calculé rk pour chaque paire consécutive tk pour une période de temps donnée tk par rapport à la période combinée tk et le suivant. Nous avons donc 316 rk valeur (bonobo 70, chimpanzé 81, gorille 78, humain 43, orang-outan 44). Après les tâches précédentes13,29nous avons testé la signification des pics isochrones (rk= 0,5) en comptant les nombres rk Valeurs dans la plage d’isochronie (0,440rk< 0,555) et les plages non isochrones (0,400rk< 0,440 et 0,555 rk< 0,600), distribué symétriquement avec un rapport de 1:1. Pour vérifier le rapport de tempo ( rk) étaient plus susceptibles de se trouver dans la plage de rapports non entiers, nous avons donc ajusté trois modèles mixtes linéaires généraux ( glmmTMBemballer30), en utilisant la distribution de Poisson (données de comptage) et spécifiez Zyformul= 1 pour tenir compte des zéros en excès. Tous les modèles incluent un décalage de poidsrk comptez par la largeur du conteneur. Le premier modèle (GLMM1) contient rk considérée comme variable de réponse, et le type de bassin d’observation (deux niveaux : isochrone ou non isochrone) comme prédicteur, les caractéristiques individuelles du sujet, son espèce, son âge (en mois) comme facteurs aléatoires imbriqués. Nous l’avons eup– évaluation à l’aide du test suivant (emmen28). Les deux autres modèles visaient à explorer d’éventuelles différences de structure rythmique selon le contexte, la même syntaxe que le premier, mais deux sous-groupes différents. Le deuxième modèle (GLMM2) à des fins d’analyse uniquementrk construit dans le jeu : c’est le seul cas où le modèle complet n’est pas significativement différent du modèle nul, ce qui indique que l’identité de la case (sur et hors isochronie) ne peut pas expliquer la variabilité de la variable de réponse. Le troisième modèle (GLMM3) pour analyser le rire produit lorsqu’on est chatouillé, nous avons réalisé le test suivant (emmen28).
Statistiques et reproductibilité
Toutes les analyses statistiques ont été effectuées dans R24. Des descriptions détaillées des modèles statistiques sont fournies dans les sous-sections pertinentes des méthodes. La taille des échantillons est rapportée tout au long du manuscrit et correspond aux mesures individuelles du rire et des intervalles (tk), rapport rythmique (rk), ou des enregistrements en fonction de l’analyse. Les copies ont été définies comme des combats ou des enregistrements individuels, et l’identification des individus et des fichiers a été incluse comme effets aléatoires pour tenir compte des mesures répétées. Les données n’ont pas été exclues, sauf pour les enregistrements qui ne répondaient pas aux critères prédéfinis consistant à contenir au moins trois appels par combat. Aucune méthode statistique n’a été utilisée pour prédéterminer la taille de l’échantillon.
Résumé du rapport
Des informations supplémentaires sur la conception de l’étude sont disponibles ici Résumé du rapport sur le portefeuille nature lié à cet article.